Из журнала Scenergy #2, Новгород, 2000
(C) Flying/DR
Упаковка анимаций в JAM
В данной статье будет рассмотрен метод
упаковки анимаций, примененный в последней
деме Digital Reality - JAM (2-е место на
CC'999).
Если Вы уже видели это demo (а я надеюсь
что видели), то вы понимаете о каких
анимациях идет речь.
Сразу скажу, что я отнюдь не являюсь
специалистом в области упаковки данных и
поэтому не могу гарантировать точность
своих высказываний, а так же правильность
употребляемой мною здесь терминологии.
В последнее время использование анимации
как части демы становится все более
популярным. Однако, как правило, люди
используют т.н. chunk'овые анимации, т.е.
анимации в разрешении 64x32 или 64x48 при
16 градациях яркости и размере "точки" 4x4
пикселя. Согласен, это неплохо. Но со
временем начинает надоедать. Кроме того,
подобный тип анимаций совершенно не
подходил для реализации наших планов
относительно JAM'а - нам нужны были
анимации именно в планарном режиме, т.е. в
разрешении 256x192 и в 2 цветах т.к. все
равно танцующие фигуры должны были быть
силуэтными. Кроме этого было необходимо
соблюсти еще несколько критериев:
- Максимально возможная степень упаковки.
- Максимально высокое быстродействие
распаковщика/плеера. Фактически было
необходимо распаковывать кадр анимации
со скоростью 50 или 25 fps.
Сразу скажу что то, что удалось сделать
при написании JAM в полной мере отвечает
описанным выше требованиям. Судите сами,
вот статистика реальных данных из нашей
демы:
Количество анимаций: 14
Суммарное количество кадров: 686
Объем распакованных данных: 1,585,314 байт
Объем упакованных данных: 162,517 байт
Степень сжатия: 10.25%
При этом анимации дополнительно можно
ужать HRUST'ом еще где-то процентов на
20-30, т.е. 2.5 стандартных TR-DOS'овских
диска анимаций с легкостью уместились в
100 с небольшим килобайт. Кроме того, могу
сказать, что если бы у нас было больше
времени, то можно было бы добиться еще
большего качества сжатия использовав две
дополнительные фичи:
- Упаковка кадров анимации с учетом того,
что кадры образуют последовательность,
т.е. реально паковать не кадры, а
различия между ними. В JAM'е же из-за
недостатка времени был использован
плеер, играющий анимации сжатые только
как набор независимых кадров. Однако в
упаковщике этот режим поддерживается, и
я могу сказать, что выигрыш при этом
получается небольшой (всего несколько
процентов).
- Дополнительная обработка кадров для
сглаживания контуров изображения. Из-за
того, что кадры анимации для JAM
вырезались вручную, их края получились
достаточно неровными что соответственно
снижает качество упаковки.
Прежде чем перейти непосредственно к
описанию алгоритмов сжатия я должен
сказать огромное спасибо Дмитрию Пьянкову,
автору таких известных программ как HRUST,
HRUM и Laser Compact. Он оказал мне
неоценимую помощь в разработке формата
упакованных данных, и именно благодаря его
советам и рекомендациям мне удалось
добиться такого качества упаковки.
Итак, прежде всего определимся с тем, что
именно мы хотим получить в результате. Нам
необходимо упаковать изображение. Причем,
поскольку данный алгоритм разрабатывался
для упаковки строго определенных видов
изображений и учитывает их специфику, то
необходимо описать, в чем состоит эта
специфика. Итак, изображение которое будет
паковаться наилучшим образом, должно быть:
- Планарное, т.е. его формат аналогичен
формату стандартного Спектрумовского
экрана, где 1 байт представляет собой 8
последовательных пикселов на экране.
- Силуэтное. Изображение представляет
собой сплошной силуэт некоторой фигуры (в
случае с JAM это фигура танцующего
человека). В идеале этот силуэт не
содержит внутренних отверстий и полутонов.
Т.е. сканированные изображения, конверсии
выполненные с использованием dithering'а,
изображения с большим количеством мелких
деталей и пиксельным "мусором" и прочие
изображения подобного рода будут жаться
плохо.
- Одиночное, т.е. в кадре изображена
только одна фигура или несколько не
связанных между собой фигур. Под
отсутствием связи здесь подразумевается
то, что в каждом байте изображения
находятся части только одной фигуры. К
связанным частям также относятся близко
расположенные части невыпуклой фигуры
(например, ноги человека стоящего прямо).
Для лучшего понимания того о чем идет речь
посмотрите на приведенные ниже картинки.
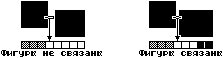
Это, конечно, не обязательное условие, но
его соблюдение улучшит качество паковки.
Теперь, когда мы разобрались с тем, какие
изображения будут паковаться наилучшим
образом при использовании данного метода,
необходимо определиться еще с двумя очень
важными составляющими, которые, по сути, и
определяют формат упакованных данных, а
значит и алгоритм упаковки. Это способ
перекодировки изображения и способ
кодирования упакованных данных.
Под перекодировкой изображения я здесь
подразумеваю то в какой последовательности
будут обрабатываться байты исходного
изображения.
Для того типа изображений, которые мы
собираемся сжимать, подходят 3 метода
перекодировки:
1) Изображение представляет собой обычный
Спектрумовский экран. Плюс этого метода в
том, что при распаковке не придется
заниматься расчетом экранного адреса при
помещении распакованного байта т.к. в
памяти байты распакованного изображения
будут расположены последовательно. Однако
при использовании данного метода можно
будет сжимать только изображения размером
с целый экран, что делает этот метод
неприменимым.
2) Изображение представляет собой спрайт
с кодировкой по строкам:
0123
4567
89AB
CDEF
Это позволит снять ограничение на
фиксированный размер анимации. Кроме того,
при данном методе пересчет экранного
адреса при распаковке необходим только при
переходе к следующей строке экрана, что
экономит время распаковки.
3) Изображение представляет собой спрайт
с кодировкой по столбцам:
048C
159D
26AE
37BF
Этот метод имеет самый высокий расход
времени на пересчет экранного адреса -
расчет производится для каждого байта.
Однако этот метод имеет одно большое
преимущество перед остальными методами.
Оно обусловлено спецификой Спектрумовского
экрана. Как вы знаете - экран Спектрума
состоит из знакомест. Каждое знакоместо
выглядит на экране как квадрат 8x8
пикселов. Однако в памяти это отнюдь не 64
байта, а всего 8 байт т.к. 1 точке на
экране соответствует отдельный бит, а не
байт. Извиняюсь за то, что говорю всем
известные вещи, но это важно для понимания
сути. Так вот, если посмотреть на то, как
расположены байты составляющие знакоместо,
то мы увидим, что они расположены
вертикально. Т.е. если расположить их в
памяти последовательно, то вероятность
того, что эти байты образуют однородную
последовательность (которая, естественно,
хорошо пакуется) намного выше, нежели при
использовании последовательности байт
образующих горизонтальную линию. А такую
последовательность байт мы как раз и
получим в случае перекодировки исходного
изображения в вид спрайта с кодировкой по
столбцам. Забегая вперед, скажу, что при
использовании этого метода качество
паковки анимаций из JAM возрастает аж в 3
(в три) раза! Так что ради подобного
увеличения качества сжатия стоит принять
определенные неудобства, связанные с
необходимостью пересчета экранных адресов.
Как вы понимаете - лучше всего выбрать
3-й метод, хотя паковщик также, на всякий
случай, поддерживает и 2-й метод.
Теперь давайте разберемся со второй
составляющей - способом кодирования данных
при паковке.
Как Вам наверняка известно - существует
множество методов упаковки данных. Однако
все методы дающие высокое качество
паковки нам в данном случае не подходят
т.к. они используют хранение упакованных
данных как битового потока, а операции с
битами на Спектруме - вещь достаточно
медленная и не соответствует требованиям к
скорости распаковщика.
"Мы пойдем другим путем!" (c) В.И.Ленин
Для увеличения скорости обработки будем
хранить упакованные данные как набор
байтов. Соответственно упакованный кадр у
нас будет представлять собой набор блоков
данных следующего формата:
+0 [byte] Тип операции. В этом же байте
для экономии места будем хранить
дополнительные флаги.
+1 [data] Длина последовательности.
+n [data] Дополнительные данные.
Естественно, что все данные кроме байта
типа операции могут менять размер или
вообще отсутствовать.
Необходимо также выбрать набор операций,
которые будут использоваться распаковщиком
для восстановления упакованного кадра.
Исходя из специфики изображения, которое
мы собираемся паковать, были выбраны
следующие типы операций (в скобках даны
названия этих операций используемые в
дальнейшем):
- Пропуск группы байт (Skip).
- Инверсия группы байт (Inverse).
- Заполнение группы байт определенным
значением (Fill byte).
- Заполнение группы байт значением #FF
(Fill #FF).
- Заполнение группы байт значением #00.
(Fill #00).
- Помещение в память спец. байта.
(Spec. byte).
- Помещение в память последовательности
байт (Sequence).
Некоторые пояснения по поводу выбранных
типов операций.
Операции "пропуск" и "инверсия" группы
байт применимы только в случае, если кадры
анимации пакуются с учетом предыдущего
кадра. Но распаковщик использованный в JAM
поддерживает распаковку только независимо
упакованных кадров и поэтому эти 2 типа
операций по сути не нужны. Однако с учетом
того, что в будущем можно будет написать и
распаковку последовательности кадров -
пришлось ввести и реализовать и эти 2 типа
операций.
Заполнение группы байт значениями #00 и
#FF вынесены в отдельные операции исходя
из специфики пакуемого изображения т.к.
именно эти значения будут встречаться
наиболее часто.
Операция "Помещение в память спец. байта"
тоже введена исходя из специфики пакуемого
изображения. Дело в том, что байты,
образующие границу силуэтного объекта
будут также встречаться достаточно часто.
А ведь всех возможных значений этих
байтов для изображения, специфика которого
была оговорена в начале статьи, всего 16:
%00000001 %11111110
%00000011 %11111100
%00000111 %11111000
%00001111 %11110000
%00011111 %11100000
%00111111 %11000000
%01111111 %10000000
%11111111 %00000000
Таким образом, вынесение этих байтов в
отдельную операцию позволит избавиться от
операции "Помещение последовательности
байт", которая применялась бы к этим
байтам и в результате мы получим выигрыш в
размере упакованного изображения.
Кроме всего перечисленного выше есть еще
пара моментов, призванных уменьшить размер
упакованного изображения.
При паковке кадров зачастую встречается
ситуация, когда есть две хорошо пакующиеся
последовательности разделенные всего одним
байтом. Типичный пример - граница объекта.
Мы имеем последовательность #FF, затем
байт границы объекта и за ним идет большая
последовательность #00. Соответственно
байт на границе объекта будет упакован как
последовательность из 1 байта, что очень
неэкономично. Поэтому для каждой операции
вводится дополнительный флаг, сохраняемый
в 0-м бите байта типа операции - признак
того, что после выполнения этой операции
необходимо будет поместить в кадр еще один
байт, значение которого записано сразу
после данных для этой операции. Есть одно
исключение из этого правила - для операции
помещения последовательности байт этот
флаг отсутствует т.к. не имеет смысла.
Также, для увеличения быстродействия
распаковщика анимаций вводится еще один
дополнительный код - признак конца кадра.
Введение этого кода позволяет избавить
распаковщик от необходимости подсчета
размера уже распакованных данных и этим
экономит драгоценное время.
Теперь, когда все типы операций описаны,
перейдем к описанию еще одной очень важной
вещи - способа кодирования длины пакуемой
последовательности.
Нам необходимо иметь возможность задания
большого размера последовательности при
использовании по возможности меньшего
объема данных. Дима Пьянков предложил
следующий метод:
Под каждую операцию отводится некоторое
определенное количество кодов. Допустим на
операцию заполнения байтом #FF отводится
50 кодов начиная с кода 80. Отняв от кода
операции значение начального кода операции
(в данном случае - 80) мы получим длину
последовательности. Бит 0 содержит признак
того, что после операции необходимо будет
сохранить дополнительный байт данных. Так
что всего мы имеем 50/2=25 различных кодов
длины последовательности. Назовем это
лимитом длины.
Итак, мы имеем длину последовательности.
Сначала проверяем - если эта длина не
равна 0, то это и будет длина, иначе
реальная длина хранится в следующем байте.
Берем этот байт и проверяем - больше ли он
лимита длины этой операции (в нашем случае
25)? Если больше - то это и есть длина.
Если же нет - то это лишь старший байт
реальной длины, а младший байт хранится
в следующем байте данных.
Таким образом, данный метод кодирования
при лимите длины N позволяет создавать
последовательности с длиной до N*256+255.
Например, для нашего случая (лимит длины
равен 25) размер последовательности может
быть вплоть до 25*256+255=6655 байт, т.е.
даже больше чем размер экрана!
Лимит длины для каждой операции свой и
зависит от того, сколько кодов отведено
для кодирования этой операции. Т.к. каждая
операция имеет свою вероятность появления
при паковке кадра, то и количество кодов
выделенных для них различно. Вот таблица
распределения кодов между операциями. В
JAM'е была использована немного другая
таблица, однако внесенные мной изменения
в результате дали повышение качества
упаковки для тестовой анимации на 3%
+----------+-----------+----------+
| Тип | Стартовый |Количество|
| операции | код | кодов |
+----------+-----------+----------+
|Skip | 0 (#00) | 32 (#20) |
|Inverse | 32 (#20) | 16 (#10) |
|Fill byte | 48 (#30) | 32 (#20) |
|Fill #FF | 80 (#50) | 50 (#32) |
|Fill #00 | 130 (#82) | 50 (#32) |
|Spec. byte| 180 (#B4) | 32 (#20) |
|Sequence | 212 (#D4) | 43 (#2B) |
|End marker| 255 (#FF) | 1 (#01) |
+----------+-----------+----------+
Ну и, как обычно, есть пара исключений из
правила:
1) Для операций Fill #FF и Fill #00 длина
последовательности в 1 байт не требуется,
т.к. ее можно закодировать помещением в
кадр соответствующего спец. байта. Поэтому
лимит длины для этих операций увеличен на
1 за счет того, что реально хранится не
лимит, а лимит-1.
2) Для End marker лимит длины не задается.
Еще пару слов скажу о формате файла для
хранения анимаций. Вообще-то их 2 - формат
для хранения отдельного упакованного кадра
и непосредственно анимации.
Формат для хранения отдельного кадра (ZXF)
+0 [data] 'ZXF' (ZX Frame). Сигнатура, по
которой можно определить формат
файла.
+3 [byte] Версия формата файла. Наличие
этого байта позволяет без труда
определить формат файла, который
может со временем меняться. На
данный момент текущая версия
формата - #01.
+4 [byte] Байт флагов. Содержимое этого
байта позволяет определить тип
упаковки который был использован
для этого файла и использовать
соответствующий плеер.
Подробнее о значении каждого
флага см. ниже.
+5 [byte] X координата левого верхнего
угла окна для вывода кадра.
+6 [byte] Y координата левого верхнего
угла окна для вывода кадра.
+7 [byte] Размер кадра по X.
+8 [byte] Размер кадра по Y.
+9 [data] Упакованные данные.
Следует заметить, что т.к. этот алгоритм
упаковки работает с последовательностью
байт, то X координата и размер по X будут
всегда кратны знакоместу. Соответственно
эти параметры задаются в знакоместах. Т.е.
значение X координаты равное 5 означает,
что левый верхний угол окна вывода кадра
расположен начиная с 5 знакоместа, а не с
5 пикселя экрана. То же самое и с размером
по X. Соответствующие параметры для Y
задаются в пикселях.
Формат для хранения анимации (ZXA)
+0 [data] 'ZXA' (ZX Animation). Сигнатура,
по которой можно определить
формат файла.
+3 [byte] Версия формата файла. Наличие
этого байта позволяет без труда
определить формат файла, который
может со временем меняться. На
данный момент текущая версия
формата - #01.
+4 [byte] Количество кадров в анимации.
+5 [byte] Байт флагов. Содержимое этого
байта позволяет определить тип
упаковки который был использован
для этого файла и использовать
соответствующий плеер.
Подробнее о значении каждого
флага см. ниже.
+6 [data] Таблица смещений начала данных
каждого кадра анимации. За точку
отсчета смещений берется первый
байт упакованных данных. Так что
смещение первого кадра всегда
будет нулевым. Размер таблицы:
2*(+4) байт, где (+4) - байт по
смещению +4 от начала файла.
+n [data] Упакованные кадры анимации. Они
располагаются последовательно и
их формат аналогичен формату ZXF
приведенному выше за исключением
отсутствия сигнатуры и версии
формата, а также байта флагов.
Прибавив адрес первого байта
данных этого раздела к каждому
элементу в таблице смещений (+6)
мы получим таблицу указателей на
каждый кадр анимации.
Как следует из описания формата - этот
формат не позволяет хранить больше 255
кадров анимации или создавать анимации
размером больше 65535 байт. Но для Speccy
это в самый раз.
Кто-то еще может указать на то, что здесь
тратится, по сути, без дела целых 4 байта
на хранение сигнатуры и версии формата.
Но, если подумать, то можно понять, что за
потерю 4 байт мы получаем возможность
точно идентифицировать формат файла. Та же
BestView "зная" формат файла этого типа
для каждой версии сможет получить точную
информацию о его содержимом. А в самом
demo можно будет хранить маленький
менеджер, который по заголовку формата
сможет определять - какой плеер нужно
использовать для этой анимации и не
потребуется каждый раз лезть в код при
изменении файла анимации.
Теперь подробнее о значении каждого бита
в байте флагов:
На данный момент определены значения для
следующих битов:
Bits 0..2 - указывают тип плеера для
данной анимации. Содержимое этих битов
определяет, какой плеер нужно использовать
для проигрывания этой анимации.
Возможные значения:
000 - Обычный плеер.
001 - Чересстрочный плеер. Отличается от
обычного тем, что выводит анимацию
не на каждую строку, а через одну. В
упакованной анимации единственным
отличием данных от нормальных будет
то, что сохраняются только четные
или только нечетные строки исходного
изображения в зависимости от того,
какое значение имеет Y координата
левого верхнего угла этого кадра.
010 - C64 плеер. Этот плеер использует
метод вывода изображения, который я
впервые увидел на C64. Этот метод
был впервые применен мной в деме
Binary Love (в начале второй части,
где вращаются кубики). Этот метод
дает эффект "разорванности" картинки
на экране и, кроме того, позволяет
обсчитывать изображение в 4 раза
меньшее, чем изображение на экране.
Соответственно единственным отличием
упакованных данных будет то, что
исходное изображение будет сжато по
X и по Y в два раза.
Значения 011..111 на данный момент пока
не определены и зарезервированы.
Хочу заметить что, по сути, эти методы
отличаются только размером изображения,
поэтому они взаимозаменяемы и любой плеер
сможет проиграть анимацию для любого типа
плееров. Естественно только, что после
распаковки другим плеером изображение
будет выглядеть сжатым/растянутым.
Bit 3 - способ перекодировки изображения.
Если этот бит сброшен - кадры упакованы с
перекодировкой по строкам, если этот бит
установлен - то использована перекодировка
по столбцам. Об этих методах перекодировки
я уже писал выше. Скажу также, что на
данный момент существует только плеер для
анимаций с перекодировкой по столбцам. Это
связано с тем, что, как я уже говорил,
этот метод дает намного большую степень
упаковки. Однако любой плеер можно без
проблем переделать под использование для
анимаций с перекодировкой по строкам.
Bit 4 - способ сжатия последовательности
кадров. Если этот бит равен 0, то кадры
анимации сжимались с учетом предыдущего
кадра. Т.е. перед тем как сжать кадр -
он накладывается по XOR на предыдущий кадр
и пакуется результат этой операции. Если
же этот бит равен 1 - то кадры анимации
упакованы независимо, каждый сам по себе.
Необходимо также учитывать тот момент, что
у кадров, упакованных с учетом предыдущего
размер окна распаковки, положение и размер
которого записаны в заголовке каждого
кадра, будут различными. Для независимо
упакованных кадров окно распаковки будет
одинаковым для всех кадров.
На данный момент есть плеер только для
независимо упакованных кадров. Это связано
с тем, что существующий алгоритм депакера
эффективен только для таких анимаций.
Необходимо также заметить, что значение
этого бита определено только в ZXA файлах,
для ZXF файлов этот бит неопределен.
Остальные биты в этом флаге для данной
версии формата неопределены и поэтому
всегда сброшены.
Ну вот, на основании всех этих данных
каждый сможет написать набор процедур для
упаковки и распаковки анимаций. Вся
необходимая информация для этого описана в
этой статье.
Но это не все. Кроме того, для того чтобы
вам легче было разобраться со всем этим и
не тратить время (которого нам всем всегда
не хватает) на то чтобы написать все это
самим - я отдаю вам для изучения и
использования свою библиотеку работы с
этими анимациями - ZXA library.
Подробно использование компонентов этой
библиотеки описано в статье ZXA library, к
которой я вас сейчас и отсылаю.