Из журнала Adventurer#11,
Ярославская область, г.Рыбинск, 17.08.2000
DEMON/XPC/CPU
GAME MAKING #2
Приветствую тебя, забредший сюда...
Речь здесь опять ( смотри ADV#10 ) о го-
веном гаме-макинге >:->
Ну, начнем со спрайт-выводилок, все
просто и ясно - бывают они:
- с попиксельными координатами вы-
вода и с знакоместовыми;
- с масочкой и без масочки;
- с атрибутами и без.
Дальше идут комбинации вышеперечис-
ленной лажи. Делить на виды по способу
организации вывода (зависит от структуры
хранения инф-ции в спрайтах) я не буду,
все равно все не перечислить, даже не
помню, как хранились спрайты в сраном
спрайт генераторе от THD (козлы), кото-
рый был для меня первой программой тако-
го рода.
Несколько слов о выводилках спрай-
тов: по моему мнению они должны соответ-
ствовать определенным условиям, напри-
мер, для меня не нужны были stack-fast
'овые, и до охереннных размеров раздек-
ранченные, т.к. юзались оба экрана, то
выводилка должна была сидеть в основной
памяти Спека (#5b00-#bfff), а кроме нее
еще много чего там сидело.
Расскажу о трех выводилках; по Y
они пиксельные, по X две из них знакоме-
стовые и одна пиксельная.
1. Х - ЗНАКОМЕСТОВАЯ БЕЗ МАСКИ
Тут все стандартно и без всяких
гребаных наворотов со стеком и др. при-
чудами, чем проще, тем меньше #бли. Но
если у тебя есть желание трахаться с
прерываниями и трассировать стек, то
флаг тебе в руки...
Итак 32 LDI - это rulez, всего 16
тактов на байт (и на моем четно-тактовом
Скорпе тоже).
Задаем координаты в DE, размер
спрайта в BC и сам спрайт в HL, делаем
CALL ssp, и он на экране (если задано не
правильно, то на экране скорее всего
появится говно). Процедурка эта ничего
не проверяет и ничего не возвращает,
т.к. это низший уровень ядра проги. Хо-
чешь - переделай или вообще лучше сделай
свою, будет чем гордиться...
ВНИМАНИЕ! В листингах присутствует
ненормативная лексика - директивы
XAS 'a.
;(C) DEMON/XPC
;Sprite x_Symbol Print without mask
;Average_Speed= 18.5 t/b (Scorp)
;Prog_Len=120 b
;--------------
;In : HL- sprite
; DE- coord (X-sim,Y-pix)
; BC- size (Y-pix,X-sym)
;--------------
ssp PUSH IX
LD IX,wo_r_ok+4; рассчитываем и
LD A,C; смещаем цикл
ADD A,A; по LDI
SUB 64; через JP (IX)
NEG
LD C,A
LD A,B
LD B,0
ADD IX,BC
LD B,A
PUSH HL
CALL adres_y; расчет адреса
EX DE,HL
POP HL
JR wo_r_ok; входим в цикл...
wo_rinc 28+
LD A,E; 4
ADD A,32; 8 (7)
LD E,A; 4
JR C,wo_r_ok; 8 (7)/12
LD A,D; 4
SUB 8; 8 (7)
LD D,A; 4
JP wo_r_ok; 10
wo_ylop INC D; 4
LD A,D; 4
AND 7; 8 (7)
JR Z,wo_rinc; 8 (7)
wo_r_ok PUSH DE; 10
LD C,D ; 4 шоб было C>32
JP (IX); 8
!ASSM 32; 32-е инструкции LDI
LDI ; 16
!CONT
POP DE; 12 (11)
DJNZ wo_ylop; 14 (13)
POP IX
RET
;------------- Расчет адреса в экране
;In: DE- X(sym), Y(pix)
;Out: HL- adres in screen
;-------------
adres_y LD L,D
LD A,E
AND 7
LD H,A
LD A,E
AND #38
RLCA
RLCA
OR L
LD L,A
LD A,E
AND #C0
RRA
RRA
RRA
OR H
LD H,A
LD A,(how_scr)
OR H
LD H,A
RET
;------------- VAR
how_scr DB #40
Такты указаны в критичных местах,
первые цифры справедливы для Скорпа ,в
скобках - для всего остального. Кстати,
на моем Скорпе тесты кажут 74884 t в
прерывании по четнo-t-вым и от 71141 до
71440 по нечетно-t-вым командам.
Переменная how_scr является опреде-
ляющей для того, с каким экраном в дан-
ный момент работает прога (не видимый, а
рабочий!), #40 для 5-го и #C0 для 7-го,-
например:
рисуем 5-й экран (how_scr=#40), а
видим 7-й, вдруг прерывание: определяем
по переменной pag_or (см.ниже), что
включен 7-й экран, меняем how_scr на #C0
и стрелку выводим на 7-ом; т.к. все GFX-
процы, работают через эту переменную, то
и адреса все будут рассчитаны для соот-
ветствующего экрана.
Можно вякать, что это тупо и надо
бы просто 5-й врубать с #C000 ( Sorry,
Elf ), но при работе с двумя экранами я
пришел именно к этому методу.
2. Х - ЗНАКОМЕСТОВАЯ С МАСКОЙ
;(C) DEMON/XPC
;Sprite x_Symbol Printer with Mask
;Average_Speed= 50 t/b (Scorp)
;Len= 287 b
;-------------
;In: HL- sprite with mask
; DE- coord X(sym), Y(pix)
; BC- size Y(pix), X=(sym)
;-------------
ssp_m PUSH IX; усе тоже самое
LD IX,wm_r_ok+3
LD A,C
ADD A,A
ADD A,A
ADD A,C
ADD A,C
ADD A,C
SUB 224
NEG
LD C,A
LD A,B
LD B,0
ADD IX,BC
LD B,A
PUSH HL
CALL adres_y
LD D,B
LD B,H
LD C,L
POP HL
JR wm_r_ok; опять цикл...
wm_rinc; 28+
LD A,C ; 4
ADD A,32; 8 (7)
LD C,A ; 4
JR C,wm_r_ok; 4 (7)/12
LD A,B ; 4
SUB 8; 8 (7)
LD B,A ; 4
JP wm_r_ok; 10
wm_ylop INC B; 4
LD A,B ; 4
AND 7; 8 (7)
JR Z,wm_rinc; 8 (7)
wm_r_ok LD E,C ; 4
JP (IX); 8
!ASSM 32
LD A,(BC) ; 8 (7) на байт экрана
AND (HL); 8 (7) накладываем маску
INC HL; 6 и байт спрайта
OR (HL); 8 (7) ложим на результат
INC HL; 6
LD (BC),A ; 8 (7) кладем в экран
INC C; 4
!CONT
LD C,E 4
DEC D 4
JP NZ,wm_ylop; 14
POP IX
RET
Спрайт должон иметь следующую
структуру: байт-маска, байт-дата, байт-
маска и т.д., как делает Sprite Land от
DR .
Насчет этих двух проц действует
следующее правило: ,
"ЛУЧШЕ ШИРЕ И КОРОЧЕ, ЧЕМ УЖЕ И
ДЛИНHЕЕ" , т.е. спрайт размером Х=32 и
Y=10 нарисуется быстрее, чем размером
Х=10 и Y=32, хотя размер в байтах одина-
ковый.
3. ПОПИКСЕЛЬНАЯ С МАСКОЙ
Сделал эту процу в основном Elf ,
XN0ByS чего-то тоже делал. Когда Костян
( Elf ) заявил, что это самое, мол, быс-
трое, то на спор я ее, родимую, зафас-
тил. Выигрыш по сравнению со старой в
среднем составил 5000-7000 тактов, но
если брать спрайт больших размеров (ис-
пытуемый кушал около 45000 тактов), то
он (выигрыш) пропорционально возрастает.
А все за счет использования недокументи-
рованных команд; думаю, что можно еще
ускорить, но влом...
;FAST PIXEL'S SPRITE WITH MASKA...
;by ELF/AURYN & XN0ByS/SG
;...FASTEST
;by DEMON/XPC'99
;IN: HL ADR_OF SPRITE
; D Coord X in pIXels
; E Coord Y in pIXels
; C -x_size symbol
; B -y_size pIXel
spr_pxm
PUSH HL
CALL adres_p
EX DE,HL
ADD A,A
PUSH BC
LD C,A
LD B,0
LD HL,rol_tab
ADD HL,BC
LD A,(HL)
INC HL
LD H,(HL)
LD L,A
LD (pxspr+1),HL
POP IY
POP HL
pxspr JP bit_0
;In IY-Y & X size
; HL-SPRITE WITH MASK
; DE-ADRES ON SCREEN
bit_0
LD C,LY
bit_0l1
LD B,C
LD LX,E
bit_0l2
LD A,(DE)
AND (HL)
INC HL
OR (HL)
LD (DE),A
INC HL
INC E
DJNZ bit_0l2
LD E,LX
CALL down_DE
DEC HY
JR NZ,bit_0l1
RET
bit_1
EX DE,HL
LD A,HY
LD HX,A
bit1_l1
LD HY,LY
LD A,L
EX AF,AF'
bit1_l2
LD BC,#ff
LD A,(DE)
SCF
RRA
RR C
AND (HL)
LD (HL),A
INC DE
LD A,(DE)
RRA
RR B
OR (HL)
LD (HL),A
INC L
INC DE
LD A,C
AND (HL)
OR B
LD (HL),A
DEC HY
JR NZ,bit1_l2
EX AF,AF'
LD L,A
CALL down_HL
DEC HX
JR NZ,bit1_l1
RET
bit_2
EX DE,HL
LD A,HY
LD HX,A
bit2_l1
LD HY,LY
LD A,L
EX AF,AF'
bit2_l2
LD BC,#ff
LD A,(DE)
SCF
!ASSM 2
RRA
RR c
!CONT
AND (HL)
LD (HL),A
INC DE
LD A,(DE)
!ASSM 2
RRA
RR B
!CONT
OR (HL)
LD (HL),A
INC L
INC DE
LD a,C
AND (HL)
OR B
LD (HL),A
DEC HY
JR NZ,bit2_l2
EX AF,AF'
LD L,A
CALL down_HL
DEC HX
JR NZ,bit2_l1
RET
bit_3
EX DE,HL
LD A,HY
LD HX,A
bit3_l1
LD HY,LY
LD A,L
EX AF,AF'
bit3_l2
LD BC,#ff
LD A,(DE)
SCF
!ASSM 3
RRA
RR C
!CONT
AND (HL)
LD (HL),A
INC DE
LD A,(DE)
!ASSM 3
RRA
RR B
!CONT
OR (HL)
LD (HL),A
INC L
INC DE
LD A,C
AND (HL)
OR B
LD (HL),A
DEC HY
JR NZ,bit3_l2
EX AF,AF'
LD L,A
CALL down_HL
DEC HX
JR NZ,bit3_l1
RET
bit_4
EX DE,HL
LD A,HY
LD HX,A
bit4_l1
LD HY,LY
LD A,L
EX AF,AF'
bit4_l2
LD BC,#ff
LD A,(DE)
SCF
!ASSM 4
RRA
RR C
!CONT
AND (HL)
LD (HL),A
INC DE
LD A,(DE)
!ASSM 4
RRA
RR B
!CONT
OR (HL)
LD (HL),A
INC L
INC DE
LD A,C
AND (HL)
OR B
LD (HL),A
DEC HY
JR NZ,bit4_l2
EX AF,AF'
LD L,A
CALL down_HL
DEC HX
JR NZ,bit4_l1
RET
bit_5
EX DE,HL
LD A,HY
LD HX,A
bit5_l1
LD HY,LY
LD A,L
EX AF,AF'
bit5_l2
LD A,(DE)
LD C,A
LD A,#ff
!ASSM 3
SLI C
RLA
!CONT
AND (HL)
LD (HL),A
INC DE
LD A,(DE)
LD B,A
XOR A
!ASSM 3
RL B
RLA
!CONT
OR (HL)
LD (HL),A
INC L
INC DE
LD A,C
AND (HL)
OR B
LD (HL),A
DEC HY
JR NZ,bit5_l2
EX AF,AF'
LD L,A
CALL down_HL
DEC HX
JR NZ,bit5_l1
RET
bit_6
EX DE,HL
LD A,HY
LD HX,A
bit6_l1
LD HY,LY
LD A,L
EX AF,AF'
bit6_l2
LD A,(DE)
LD C,A
LD A,#ff
!ASSM 2
SLI C
RLA
!CONT
AND (HL)
LD (HL),A
INC DE
LD A,(DE)
LD B,A
XOR A
!ASSM 2
RL B
RLA
!CONT
OR (HL)
LD (HL),A
INC L
INC DE
LD A,C
AND (HL)
OR B
LD (HL),A
DEC HY
JR NZ,bit6_l2
EX AF,AF'
LD L,A
CALL down_HL
DEC HX
JR NZ,bit6_l1
RET
bit_7
EX DE,HL
LD A,HY
LD HX,A
bit7_l1
LD HY,LY
LD A,L
EX AF,AF'
bit7_l2
LD A,(DE)
LD C,A
LD A,#ff
SLI C
RLA
AND (HL)
LD (HL),A
INC DE
LD A,(DE)
LD B,A
XOR A
RL B
RLA
OR (HL)
LD (HL),A
INC L
INC DE
LD A,C
AND (HL)
OR B
LD (HL),A
DEC HY
JR NZ,bit7_l2
EX AF,AF'
LD L,A
CALL down_HL
DEC HX
JR NZ,bit7_l1
RET
down_HL
INC H
LD A,H
AND 7
RET NZ
LD A,L
ADD A,32
LD L,A
RET C
LD a,H
SUB 8
LD H,A
RET
down_DE
INC D
LD A,D
AND 7
RET NZ
LD A,E
ADD A,32
LD E,A
RET C
LD A,D
SUB 8
LD D,A
RET
adres_p
LD A,E
AND A
RRA
SCF
RRA
AND A
RRA
XOR E
AND #f8
XOR E
LD H,A
LD A,D
RLCA
RLCA
RLCA
XOR E
AND #c7
XOR E
RLCA
RLCA
LD L,A
LD A,D
AND #07
RET
rol_tab
DW bit_0,bit_1,bit_2,bit_3
DW bit_4,bit_5,bit_6,bit_7
Смысл в следующем: вычисляется на
сколько придется роллировать байты
спрайта с маской, из таблицы берется
соответствующая проца, и процесс цикла
начинается. Спрайт имеет такую же струк-
туру, как описывалось выше. Наверно в
этой проце можно че-нибудь подчистить,е-
сли есть желание, хотя работает она без
проблем и уже довольно долго нами юзает-
ся в таком виде.
Все эти выводилки работают с монох-
ромными спрайтами, т.к. вывести атрибуты
с точностью до пиксела по Y очень и
очень проблематично >:->
Прежде чем перейти к следующей час-
ти своего повествования, хочу рассказать
о том, как у меня свапуется память и эк-
ран.
;-------------------Page lister
;In: A- page logic nomber (0...7),
; IF A=#FF THEN GOTO old_pag
pager EX AF,AF'
LD A,R
JP PE,pg_n_im
LD A,R
pg_n_im PUSH AF
DI
EX AF,AF'
AND A
JP M,old_pag; A=0...7
pg_f_op LD (sav_pag),A ; for OLD_PAG
now_pag EQU $+1
LD A,7
LD (old_pag+1),A
sav_pag EQU $+1
LD A,0
LD (now_pag),a
pg_f_sw AND 7; for SCR_SWP
pag_or EQU $+1
OR 0
OUT (#fd),A
LD (23388),A
POP AF
DI
RET PO
EI
RET
old_pag LD A,0
JR pg_f_op
;----------------------Screen Swaper
;In: A- 0 is #4000, other is #C000 viewing
scr_swp EX AF,AF'
LD A,R
JP PE,sw_n_im
LD A,R
sw_n_im PUSH AF
DI
EX AF,AF
OR A
LD A,(pag_or)
JR NZ,sw_is_7; IF A=0 THEN scr#5
RES 3,A
sw_f_7 LD (pag_or),A
LD A,(now_pag)
JR pg_f_sw
sw_is_7 SET 3,A
JR sw_f_7
;----------------- #FD mask detecter
;Out: A- Mask for pager
fd_mask LD A,#10
LD BC,#7ffd
OUT (C),A
LD HL,#ffff
LD E,(HL)
LD A,#50
LD (HL),A
OUT (C),A
CP (HL)
LD A,#10
OUT (C),A
LD (HL),E
RET NZ
LD A,#50
RET
Все вышеперечисленные процы состав-
ляют один пакет для работы с памятью 128
Кб.
- Проца fd_mask запускается один
раз в самом начале для определения 512-
ти килограммовых компов, если нет, то
щелкаем память с включенным 6-м битом
( для Скорпа а ).
- Проца pager свапует 128-ю память,
запоминает текущую страницу в now_pag,
предыдущую в old_pag и все свапует через
pag_or. Mаразм с регистром R и определе-
нием состояния прерываний взят из статьи
Ивана Рощина , за что огромное ему спа-
сибо. Таким макаром у меня ни разу не
было глюков по определению текущей стра-
ницы. А почему щелкаю по #FD, а не по
#7FFD? Да вот нравится так.
- scr_swp работает через pager,
поэтому когда щелкаю память не болит го-
лова о том, какую маску ставить для эк-
рана.
Ну теперь про INT (прерывания).О-
чень рулезная вещь, эти самые прерыва-
ния, можно вешать на них, что хочешь,
хоть весь движок. Но лучше повесить та-
кие вещи, как сканирование кнопок и мы-
ши, движение курсора (если он присутст-
вует), какие-нибудь фишки, типа мини-ск-
ролла с хелпом, либо небольшой анимации
где-нибудь в углу экрана и, конечно, му-
зыку и эффекты в конце.
При работе с INT может возникнуть
множество неприятностей, все даже не
предсказать; расскажу о своих.В ADV#10
был приведен мой обработчик прерываний,
аналогичный сидит в "Full Shit" , в ко-
тором:
- маленькая проца по переключению
видимого экрана, юзает глобальные пере-
менные NOW_PAG, PAGE_OR;
- сохраняется номер текущей страни-
цы памяти и определяется видимый экран,
при этом сохраняется, а затем меняется
переменная how_scr;
- врубается страница #7, т.к. в ней
сидят все процы. Следует учесть, что
INT-таблица содержит 257 байт и находит-
ся во 2-м банке, чтоб хоть как-то не
обидеть оригинальный Спек . На возможный
вопрос: "Почему 7-й банк?" , ответ та-
ков: юзаются оба экрана, места в
#5B00-#BFFF мало,а в 7-ом за вычетом эк-
рана и скрина локации остается целых 3
кило.
- восстанавливается экран под кур-
сором, но если ранее сработало переклю-
чение видимого экрана, то дерьмо со ста-
рого не восстанавливается;
- сканируется клава на предмет на-
жатия кнопок "6,7,8,9,0,Break,Q,A,O,P,S-
pace" и движения мыши (на ПЦ - эмулях
какой-то голюн с нашим драйвером: ПЦ
МАСТ ДАЙ);
- идет обращение к проце под именем
INT_GFX. Это и есть разные фишки, сос-
тоит в основном из кучи векторов, кото-
рые меняются в зависимости от действий
геймера, например: появляется менюха,
где крутится предмет (надо отрубить лам-
почку на фонаре, а потом повесить вра-
щающийся предмет, а если вызвать карман,
то 4-е предмета; мультики тоже играются
по INT) или диалоговое окно, все по INT
на х..;
- запоминается кусок в новом месте,
если было перемещение (иначе в старом),
рисуется курсор, после всех наворотов,
чтоб не попасть под какой-нибудь спрайт
или текст;
- в последнюю очередь играется му-
зон и для прикола меняются атрибуты на
светофоре;
- восстанавливаем страницу памяти,
переменную how_scr и назад.
Первый глюк возник, когда я решил
все заоптимизить: убрал собственные про-
цы вывода графики из прерываний, чтоб
все делалось через единые процы. И тут
началось... На экране стало появляться
всякое дерьмо, без всякой закономернос-
ти, иногда вообще все висло или сбрасы-
валось. А при трейсе все работало без
проблем. Такие глюки ненавижу, т.к. при-
чина сразу-то и не ясна. А вся херня бы-
ла из-за того, что в старом варианте вы-
водилки сохранялись локальные переменные
(размер спрайта) и при попадании на INT
они киллились, т.к. INT тоже юзал эти
процы. ВЫВОД: если процу юзают все, то
при ее работе все переменные надо хра-
нить на регистрах или толкать их в стэк,
иначе в прерываниях придется сохранять
все переменные.
Второй глюк возник с переключением
экранов, но об этом я, по-моему, уже го-
ворил...
В общем, если все в проге тщательно
проверить, то глюков обычно возникает
мало и не советую вешаться на IM 1, хотя
кому как нравится, хоть на IM 0 работай-
те >:->
Теперь о структуре "Full Shit" ,
которая оставляет желать лучшего, но что
есть, на том и кашу сварим...
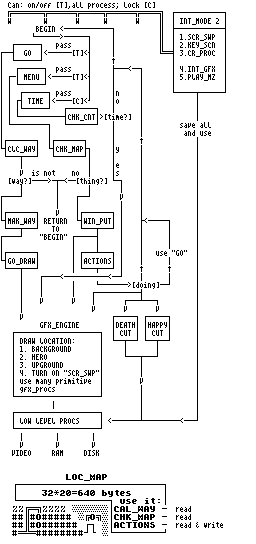
ПОЯСНИЛОВА
1) Обозначения:
[T] - порог (#0 или #С9);
[C] - порог-счетчик (пропускает че-
рез n-ое кол-во вызовов;
[time?] - условие (например: время);
2) Подпроги:
GO: - проца, отвечающая за переме-
щение героя;
CLC_WAY - просчет пути, если нет, то
нет перемещения;
MAK_WAY - иначе делает специальный уп-
равляющий массив;
GO_DRAW - работа со спрайтами переме-
щения по упр. массиву.
MENU: - действия с предметами;
CHK_MAP - проверяет статус курсора "на
предмете или нет",
если нет, то игнорирует юзе-
ра
WIN_PUT - иначе выводит окно действий
и ждет действий геймера;
ACTIONS - производит выбранные дейст-
вия, сопровождая это дело
выводом сообщений и анима-
ции, и согласно им делает
переход на соотв. процу ли-
бо возвращается в основной
цикл.
TIME: - постоянно перерисовывает иг-
ровой экран;
CHK_CNT - периодически добавляет раз-
ную анимацию (автобус, выши-
бала, герой...)
INT_MODE2 - контролирует все процессы с
помощью "порогов входа" в
процы (NOP or RET), свапует,
сканирует, рисует и поет...
GFX_ENGINE - участвует всегда в перери-
совке экрана либо выводе
чего-либо на экран.
LOW LEVEL - утилиты-примитивы, работаю-
PROCS щие именно с ресурсами маши-
ны.
LOC_MAP - это массив размером 32*20
элементов, являющийся картой
локации. В основном исполь-
зуется при расчете пути и
работе с предметами.
Now пойдет речь о процедуре рассче-
та пути в карте локации для того самого
мудака, которого ты видел в "Full
Shit" .
Алгоритм взят у Славы Медноногова
(который его тоже где-то взял и т.д. и
т.п.) из его статьи в одном из ZX-FОRMAT
'ов. Для начала лучше почитать эту
статью, а уж потом суйся сюда, т.к. я
прос-то приведу ассемблерный вариант
этого метода...
Сразу скажу, что это дело для меня
оказалось несколько проблематичным, т.к.
мой чиж (ну, персонаж) получился не эле-
ментом 1х1, а педрюком 1х4. Поэтому я
просто зае...ся точить прогу для этого
говнюка, чтоб он хоть как-то нормально
ходил по локации, тем более из-за огра-
ничений по памяти он не мог ходить по
диагонали. В общем процесс написания
этого куска движка затормозил вообще
весь процесс.
Ладно, вот вообщем оно-самое:
;(C) DEMON / XPC'99
;----------------------------
;Wawe Algoritm for Search Way
;Main idea V.Mednonogov
;Realized by ME,of course...
s_cod EQU #50; Start COD
gc_mint EQU s_cod+45; MAX Iteration
;-----------------
go_wawe RET ; Turn
LD a,#c9
LD (go_wawe),a
;-------------------- Make Work DIM 34*22 =748 b
;делается окантовочка, чтоб лишний раз не проверять выход
;за границу массива
LD b,20
LD hl,#6200; MAP_LOC
LD de,gc_wdim+35
gd_lop LD c,H
!ASSM 32
LDI
!CONT
INC de
INC de
DJNZ gd_lop
;-------------------- Set Fin & Start inside GO_DIM
;в скопированной карте ставим код СТАРТ и ЦЕЛЬ
gc_ctar LD bc,0
LD a,C
SUB 4
LD c,A
CALL gc_ccrd
LD (hl),128; Target Cod
gc_csrt LD bc,0
LD a,C
SUB 4
LD c,A
CALL gc_ccrd
LD (hl),s_cod; Start Cod
INC hl
LD (hl),s_cod
INC hl
LD (hl),s_cod
INC hl
LD (hl),s_cod
LD lx,s_cod
;-------------------- MAIN ()
gc_main CALL gc_sway
JR nz,gc_found
DEC a
LD (go_way),a ; #FF
RET
;----------------- Make way
; Если нашли цель...
gc_found EXX
LD hl,gcb_way-2
EXX
LD c,LX
INC lx
INC lx
LD de,34
gc_b_lp DEC c
CALL gc_lb
JR z,gcb_fin
CALL gc_rb
JR z,gcb_fin
CALL gc_db
JR z,gcb_fin
CALL gc_ub
JR z,gcb_fin
INC c
LD a,LX
CP c
RET c
JR gc_b_lp+1
;----------------- Found iteration (-1)
gcb_fin LD a,B
EXX
LD (hl),A
DEC hl
EXX
LD (hl),#81
JR gc_b_lp
;----------------- Make normal way_Map
gc_reway POP af
LD a,B
EXX
LD (hl),A
LD de,go_way
gcrw_lp LD b,(HL)
LD a,B
CP #ff
JR z,gcrw_end
CALL gcw_sub
LD (de),A
INC hl
INC de
JR gcrw_lp
gcrw_end LD (de),A
JP rewayer
;----------------- Invert way_step
gcw_sub LD a,"L"
CP b
LD a,"R"
RET z
CP b
LD a,"L"
RET z
LD a,"U"
CP b
LD a,"D"
RET z
LD a,"U"
RET
;----------------- Back_search
gc_lb LD b,"L"
DEC hl
LD a,(HL)
CP s_cod
JR z,gc_reway
CP c
RET z
INC hl
RET
;-----------------
gc_rb LD b,"R"
INC hl
LD a,(HL)
CP s_cod
JR z,gc_reway
CP c
RET z
DEC hl
RET
;-----------------
gc_ub LD b,"U"
AND a
SBC hl,DE
LD a,(HL)
CP s_cod
JR z,gc_reway
CP c
RET z
ADD hl,DE
RET
;-----------------
gc_db LD b,"D"
ADD hl,DE
LD a,(HL)
CP s_cod
JR z,gc_reway
CP c
RET z
AND a
SBC hl,DE
RET
;-------------------- Is Way being ?
;If no way then A=0
gc_sway LD a,LX
LD hl,gc_wdim+35
LD bc,679
gc_cpir CPIR
JR z,gc_l1
INC lx
LD a,gc_mint
CP lx
JR nz,gc_sway
XOR a
RET
;----------------- I_Cod founded
gc_l1 PUSH hl,BC
DEC hl
LD (element),hl
CALL gc_left
CALL gc_right
CALL gc_down
CALL gc_up
POP bc,HL
LD a,LX
JR gc_cpir
;-------------------- STEP LEFT
gc_left
element EQU $+1
LD hl,0
DEC hl
LD a,(HL)
OR a
RET p
CP 128
JR z,glo_end
LD a,LX
INC a
LD (hl),A
RET
;-------------------- STEP RIGHT
gc_right LD hl,(element)
INC hl
gc_v_jr LD a,(HL)
OR a
RET p
CP 128
JR z,glo_end
LD a,LX
INC a
LD (hl),A
RET
;-------------------- STEP DOWN
gc_down LD hl,(element)
LD bc,34
ADD hl,BC
gcu_jr PUSH hl
CALL gc_c_4b
POP hl
JP m,gc_c_ok
RET
;-------------------- STEP UP
gc_up LD hl,(element)
LD bc,34
AND a
SBC hl,BC
JR gcu_jr
;-------------------- UP or DOWN way is OK!
gc_c_ok
LD a,128
EX af,AF'
LD a,LX
INC a
!ASSM 4
EX af,AF
CP (hl)
JR z,glo_end
EX af,AF'
LD (hl),A
INC hl
!CONT
RET
;-------------------- Check 4 bytes
gc_c_4b LD a,(HL)
INC hl
AND (hl)
INC hl
AND (hl)
INC hl
AND (hl)
RET
;-------------------- It's START !!!
glo_end POP de,DE ,DE
OR a
RET
;----------------- In BC- R (X,Y) > Out HL- Adr of ...
gc_ccrd INC c
INC b
LD a,B
LD b,C
LD hl,gc_wdim
gc_mlp LD de,34
ADD hl,DE
DJNZ gc_mlp
ADD a,L
LD l,A
LD a,0
ADC a,H
LD h,A
RET
!ASSM !off
;-------------------- In HL- IL in DIM> Out DE- X,Y
gc_c_el LD de,0
LD bc,34
AND a
gc_dlp SBC hl,BC
JR c,dv_end
JR z,dv_end+1
INC e
JR gc_dlp
dv_end ADD hl,BC
LD d,L
DEC e
DEC d
RET
!CONT
;----------------- Very Fatly array
gc_wdim DS 748,#3030
go_way DS 50,#ffff
gcb_way
Вначале карта локации копируется в
буфер, равный размером ей самой, чтоб не
обосрать ее родимую своими итерациями.
Как видно не вооруженным взглядом,
массивно юзается команда CPIR, так, я
думаю, быстрее получается, хотя я мало
чего оптимизил, итак времени утрахал на
саму процу. Если ты все-таки удосужился
прочесть ту статью, про которую я упомя-
нул ранее, то тебе, друг мой, все будет
ясно... Командой CPIR ищем итерацию,
проверяем ее на вшивость, потом ищем
другую и так до конца массива. Я думаю,
все предельно ясно.
Когда весь массив обработан (забит
дерьмом), начинаем обратный отсчет, пока
не приходим к цели.
Делается это все довольно мудово, и
даже заметно в игре, хотя INT, конечно,
не стопорится >:->
Максимальное время на расчет пути
уходит, когда этого пути просто нет. То-
гда массив 32х20 элементов полностью за-
муживается и у меня это отнимает аж 13
прерываний, то бишь 900 000 тактов !!!
Мудово...
Так как предметы на локации у меня
являются непроходимыми, то при указании
стрелкой на них выбирается уже заранее
забитые координаты допустимого места,
куда может быть просчитан путь для моего
мудака. Т.е. если ты выберешь, например,
вышибалу, то программа определит, что ты
выбрал предмет, и возьмет из таблицы
координаты для него (точнее для героя,
чтоб подойти к предмету) и подсунет их
считалке пути, а не реальные координаты
курсора, как это было бы иначе.
И еще... Проца хождения героя у ме-
ня сделана таким образом, что она рабо-
тает через команды (понятные только ей,
of couse). В специальном буфере ей пере-
дается строка команд, которые надо вы-
полнить, типа: "L,10,U,2,R,3,ff" - это
означет, что надо сделать 10 шагов вле-
во, потом 2 вверх и затем 3 шага вправо,
#FF - end.Все просто, но зато очень удо-
бно, теперь переделывая движок под цвет-
ные спрайты, я просто поменяю значения в
таблице размеров спрайтов и все! Так что
не удивляйся значениям типа "L" или "D"
в вышеприведенном коде.
Также сделаны и другие процы,так
что прошу мотать на ус...
* * *
Итак, пипл, прошло довольно много
времени с момента написания первой части
статьи, поэтому можете считать все выше-
написанное полным отстоем.
"А ЧТО не отстой ?" - спросишь ты
меня, мой дорогой друг. Все, что я или
ты сделал является отстоем, т.к. ТЫ ЭТО
УЖЕ СДЕЛАЛ! А вот то, чего мы пока не
можем - по сути и является для нас само-
целью.
Тут недавно узнал такую вещь - мас-
ку для спрайта можно хранить черезстроч-
но, т.е. в ДВА раза меньше! Такая прос-
тая и крутая идея, а сама по себе ни
хрена ни пришла, эх, если б раньше
знать... Для тех, кто не понял: у маски
хранятся только четные или, наоборот,
нечетные линии. При выводе недостача ко-
мпенсируется дублированием линий. Все
просто - а спрайт занимает аж в 1,5 раза
меньше места (например, при размере 16
кило имеем экономию аж в 6 кило!). Я ду-
маю эта фишка давно известна гейммэйке-
рам, но я лично благодарен VOLGASOFT за
данную идею. Можно с этой фигней экскре-
ментировать как угодно, может у кого
вообще получится какой-нибудь рулез.
Ща ANT и Vaniac перерисовывают с
нуля графику для FULL SHIT , и т.к. она
вся цветная, то соответственно мне приш-
лось столкнуться с рядом проблем...
Спрайты рисуются спец-методом
(рис.1):

Cпрайт рисуется какими угодно инка-
ми и паперами, но по границе должон не
использовать цветов, это окантовка поз-
воляет квадратную атрибутную графику
превратить во вполне приемлемую картину.
На рис.2 показана суть метода:

Все геморы (от слова "геморой") на-
чинаются, когда всю эту туеву хучу кусо-
чков надо вывести на экран как единое
целое. Тут, в принципе, нет ничего особо
сложного, но я сделал так:
1. Все "куски" представляют собой
отдельные спрайты, цветные выводятся как
спрайт с атрибутами (PUT), а окантовка
как простые (LINES) по OR-методу (правда
можно и по маске, но тактов жрать больше
будет, а эффектом не особо отличается).
2. Соответственно пишем (или берем)
програмку для вывода спрайтов данного
формата (хранить и выводить можете как
угодно, у меня таким методом: 8 линий
данных, потом для них линия атрибутов,
снова 8 линий...) и делаем менеджер...
3. "Куски" одного спрайта хранятся
у меня в одном массиве:
+0 X,Y (у первого всегда по нулям)
+2 X_SIZE,Y_SIZE
+4 Смещение до следующего спр. (NN)
+6 Тип спрайта (ATTR,LINES... = 0,1,...)
+7 Сам спрайт
.. ............
.. ............
+NN X,Y относительно самого первого спр.
NN+1 X_SIZE,Y_SIZE...
... и так далее...
Вот теперь пишем менеджер, который
будет все эти массивы разгребать и ре-
шать, какой выводилкой рисовать следую-
щий "кусок" и где его рисовать (перево-
дить относительные корды в реальные).
Понятно, что все это будет работать
не так быстро, как хотелось бы, но вопе-
рвых, вполне нормально, а во-вторых -
оптимизация не знает границ ! Можно уже
готовые массивы конвертить в другой фор-
мат таким образом, чтобы не пересчиты-
вать для каждого "куска" корды. Мне лич-
но в лом, но если будет тозить, то, ко-
нечно, я это сделаю... А так, можно кон-
вертить уже готовые массивы "кусков"
так, чтобы не пересчитывать каждый раз
корды для них, ясно ?
Ну ладно, на хрен, достало писать,
пока!